用量统计
下载
聚焦模式
字号
功能概述
用量排行(仅语言模型):按服务、模型、API Key 维度对 Token 消耗进行总量汇总与 Top 排行,支持下载明细数据。
用量趋势:以图表形式展现各项用量指标随时间的变化趋势,支持按模型、服务、API Key 多维度筛选。
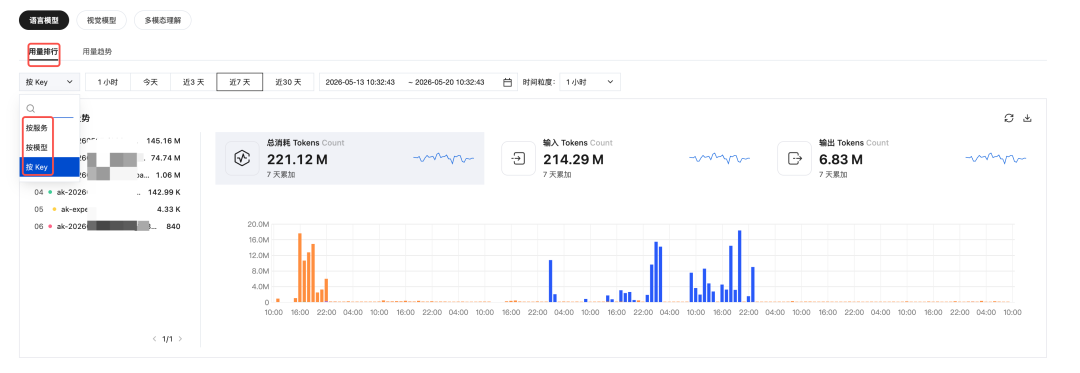
用量排行
注意:
用量排行功能当前仅在语言模型标签页下提供,视觉模型与多模态理解暂不支持。
针对语言模型的 Token 消耗,提供按 服务 / 模型 / API Key 维度的总量汇总与 Top 排行,便于您快速识别用量最高的资源、定位异常消耗。
统计维度
进入语言模型 > 用量排行标签页,可在左上角下拉框中切换以下统计维度:
统计维度 | 说明 | 典型用途 |
按服务 | 按在线推理服务汇总 Token 消耗 | 查看哪个推理服务用量最高 |
按模型 | 按模型 ID 汇总 Token 消耗 | 对比不同模型的使用占比 |
按 Key | 按 API Key 汇总 Token 消耗 | 定位高消耗 Key、按业务线核算 |
时间范围与粒度
时间范围:支持 1 小时、今天、近 3 天、近 7 天、近 30 天,或自定义起止时间。
时间粒度:支持按指定粒度(如 1 小时)汇总趋势数据。
展示内容
页面同时呈现以下三类信息:
总量卡片:在选定时间范围内的 总消耗 Tokens、输入 Tokens、输出 Tokens 总计。
排行榜:左侧列表展示选定维度下的 Top 资源(含资源名称与 Token 总数)。
趋势图:右侧柱状图按时间粒度展示各资源在不同时间区间内的消耗分布,便于识别用量峰值时段。
下载明细数据
排行榜右上角提供下载入口,单击下载图标即可将当前查询条件下的排行明细数据导出为本地文件,便于进一步对账或离线分析。
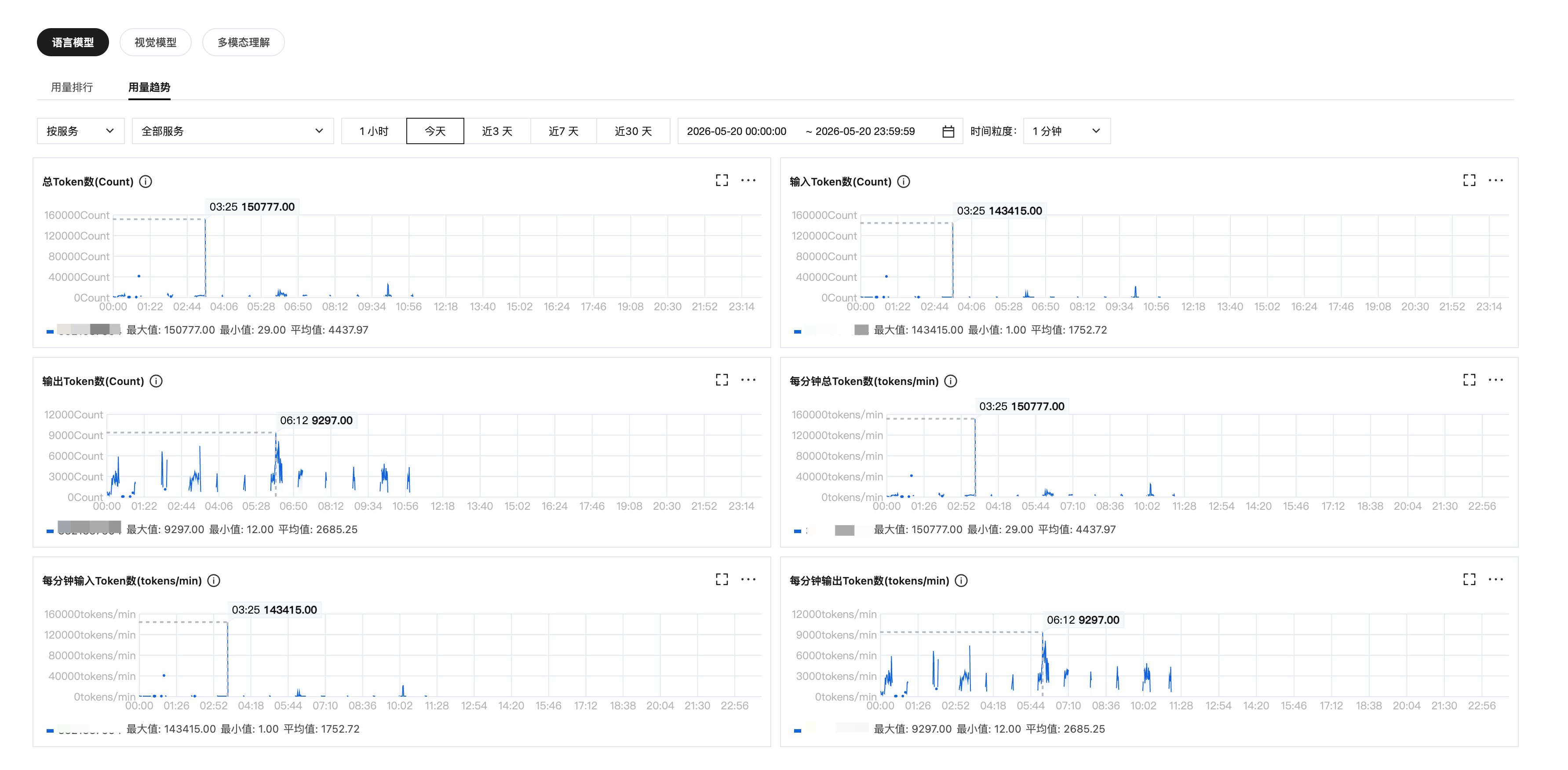
用量趋势
按模型维度汇总调用数据,支持按模型类型分类查看。
分类筛选
页面顶部提供分类标签,快速筛选不同模型类型,同时支持按在线推理服务、API Key 筛选,查看特定服务的调用情况。
模型类型 | 包含模型 |
文本生成 | DeepSeek V4、GLM-5、kimi-k2.5、MiniMax-M2.5 等 |
调用指标
各模型在选定时间范围内的关键调用指标,统计粒度支持 1分钟 / 5分钟 / 1小时:
字段 | 模型类型 | 说明 |
总 Token 数 | 文本生成 | 输入 Token 数 + 输出 Token 数。 |
输入 Token 数 | | 请求(Prompt)部分消耗的 Token 数量,包含 cache。 |
输出 Token 数 | | 模型响应(Completion)部分消耗的 Token 数量。 |
每分钟总 Token 数 | | 每分钟输入 Token 数 + 每分钟输出 Token 数。 |
每分钟输入 Token 数 | | 每分钟输入侧的 Token 吞吐量(tokens/min)。 |
每分钟输出 Token 数 | | 每分钟输出侧的 Token 吞吐量(tokens/min)。 |
读缓存 Token 数 | | 单位时间内命中缓存的 Token 数。 |
写入缓存 Token 数 | | 单位时间内创建缓存的 Token 数(部分模型支持)。 |
时间 | 所有模型 | 请求时间区间。 |
用量趋势图
以可视化图表呈现调用趋势,每项指标均提供最大值、最小值、平均值三项统计摘要,帮助用户快速识别用量峰值与整体趋势。
文本生成
提供六项 Token 维度的趋势监控:
Token 消耗趋势:总 Token 数 / 输入 Token 数 / 输出 Token 数随时间的变化走势
Token 吞吐趋势:每分钟总 Token 数 / 每分钟输入 Token 数 / 每分钟输出 Token 数的并发量变化
文档反馈